Wenn ich über KI-Agenten in Unternehmen spreche, geht es selten um ein einzelnes Modell und fast nie nur um einen Prompt. Der eigentliche Kern ist der Loop: ein wiederholbarer Ablauf aus Kontext aufnehmen, entscheiden, handeln, beobachten, prüfen und beenden.
Ohne diesen Loop bleibt ein KI-System ein Assistent, der Text erzeugt. Mit einem guten Loop wird daraus ein System, das Arbeit strukturieren kann: recherchieren, APIs aufrufen, Zwischenergebnisse bewerten, Fehler erkennen, Menschen einbeziehen und am Ende ein Ergebnis liefern, das nachvollziehbar genug für den betrieblichen Einsatz ist.
Was ist ein Agent Loop?
Die einfachste Definition lautet: Ein Agent Loop ist eine Schleife, in der ein Modell wiederholt entscheidet, ob es schon fertig ist oder ob es noch einen nächsten Schritt ausführen muss. Dieser nächste Schritt kann ein Tool-Aufruf sein, eine Suche, ein Datenbankzugriff, eine Code-Ausführung, ein Rückfrage an einen Menschen oder eine interne Bewertung des bisherigen Ergebnisses.
LangChain beschreibt einen Agenten sehr pragmatisch als Modell, das Werkzeuge in einer Schleife aufruft, bis die Aufgabe abgeschlossen ist. LlamaIndex formuliert den Kern ähnlich: Eingabe verarbeiten, entscheiden, ob ein Tool genutzt oder eine Antwort gegeben wird, Tool ausführen, Ergebnis zurück in den Kontext legen und wiederholen, bis keine weiteren Tools nötig sind.
Für mich ist dabei wichtig: Der Loop ist nicht Magie. Er ist Architektur. Er braucht Zustand, Abbruchkriterien, Tool-Grenzen, Fehlerbehandlung, Kostenkontrolle, Logging und klare Verantwortlichkeiten. Ein Agent ohne Stop-Regel ist kein intelligenter Mitarbeiter, sondern ein Prozess mit unklarer Laufzeit.
Die Grundform: Reason, Act, Observe
Viele heutige Agenten lassen sich auf eine Grundform zurückführen: Das Modell denkt über den nächsten Schritt nach, führt eine Aktion aus und bekommt eine Beobachtung zurück. Das ReAct-Paper hat diesen Zusammenhang früh sauber beschrieben: Reasoning und Acting werden nicht getrennt, sondern ineinander verschränkt. Das Modell nutzt Zwischengedanken, um Pläne zu aktualisieren, und Aktionen, um externe Informationen aus der Umgebung zu holen.
In der Praxis sieht das vereinfacht so aus: Der Nutzer stellt eine Aufgabe. Das Modell entscheidet, dass es Informationen braucht. Es ruft ein Tool auf. Das Tool liefert ein Ergebnis. Das Modell bewertet dieses Ergebnis und entscheidet, ob ein weiterer Tool-Aufruf nötig ist oder ob eine finale Antwort möglich ist.
Diese Grundform ist der Standard für viele Such-, Recherche-, Coding- und Support-Agenten. Sie funktioniert gut, solange Werkzeuge klar beschrieben sind, die Aufgabe begrenzt ist und der Loop nicht beliebig lange laufen darf.
Welche Formen von Agent Loops gibt es?
1. Tool-Calling Loop
Der Tool-Calling Loop ist die wichtigste Basisform. Das Modell ruft Funktionen, APIs oder MCP-Tools auf und verarbeitet die Ergebnisse in weiteren Modellaufrufen. OpenAI Agents SDK, LangChain, LlamaIndex und Pydantic AI kapseln genau diesen Ablauf unterschiedlich stark.
Der Vorteil ist Einfachheit. Ein Agent kann dynamisch entscheiden, ob er zum Beispiel eine Datei lesen, eine Suche starten oder einen Kalender prüfen muss. Das Risiko liegt in falschen Tool-Aufrufen, unnötigen Wiederholungen und unklaren Abbruchbedingungen.
2. Plan-and-Execute Loop
Beim Plan-and-Execute-Loop trennt man Planung und Ausführung. Zuerst entsteht ein Plan mit Teilaufgaben. Danach werden diese Schritte nacheinander oder parallel abgearbeitet. Nach jedem Schritt kann der Plan angepasst werden.
Dieses Muster eignet sich für längere Aufgaben: Migrationen, Recherchen, Dokumenterstellung, Testläufe oder komplexe Analyseprozesse. Es macht Agenten nachvollziehbarer, weil der Plan sichtbar und prüfbar ist. Gleichzeitig kann ein schlechter Anfangsplan den gesamten Loop in die falsche Richtung treiben.
3. Reflection Loop
Reflection Loops erzeugen ein Ergebnis, bewerten es und verbessern es anschließend. Self-Refine beschreibt diesen Ablauf als Feedback-und-Refine-Schleife. Reflexion geht einen Schritt weiter und lässt Agenten aus Feedback sprachliche Erinnerungen ableiten, die spätere Versuche verbessern sollen.
Dieses Muster passt gut zu Texten, Code, Architekturvorschlägen, Testfehlern oder Dokumenten. Es ist aber nur sinnvoll, wenn Bewertungskriterien existieren. Ohne klare Kriterien dreht sich ein Reflection Loop schnell um Formulierungen, ohne die Qualität wirklich zu erhöhen.
4. Evaluator-Optimizer Loop
Der Evaluator-Optimizer Loop ist die robustere, produktionsnähere Variante der Selbstkritik. Ein Generator erstellt ein Ergebnis. Ein Evaluator prüft es gegen definierte Kriterien. Danach verbessert der Generator das Ergebnis, bis es akzeptiert wird oder ein Iterationslimit erreicht ist.
Microsoft nennt dieses Muster auch Maker-Checker, Generator-Verifier, Critic Loop oder Reflection Loop. Anthropic beschreibt Evaluator-Optimizer als eines der zentralen Workflow-Patterns für agentische Systeme. Für Unternehmen ist dieses Muster besonders relevant, weil es Qualitätssicherung explizit macht.
5. Search- oder Tree-of-Thoughts Loop
Tree of Thoughts erweitert lineares Denken zu einer Suche über mehrere mögliche Lösungswege. Das Modell erzeugt nicht nur einen nächsten Schritt, sondern mehrere Kandidaten, bewertet sie und verfolgt vielversprechende Pfade weiter. Bei schwierigen Planungs- oder Kombinationsproblemen kann das deutlich besser sein als ein einzelner linearer Gedankengang.
Der Preis ist höherer Aufwand. Mehr Kandidaten bedeuten mehr Modellaufrufe, mehr Bewertung und mehr Steuerungslogik. Für alltägliche Business-Prozesse ist das oft zu teuer. Für komplexe Entscheidungs- oder Optimierungsaufgaben kann es aber ein starkes Muster sein.
6. Multi-Agent Loop
Multi-Agent Loops verteilen Arbeit auf mehrere spezialisierte Agenten. Die Schleife liegt dann nicht nur innerhalb eines Agenten, sondern zwischen Agenten: delegieren, antworten, prüfen, weitergeben, zusammenführen.
OpenAI unterscheidet hier grob zwischen Manager-Pattern und Handoffs. Beim Manager-Pattern behält ein zentraler Agent die Kontrolle und ruft Spezialagenten wie Werkzeuge auf. Bei Handoffs übernimmt ein anderer Agent die Konversation. Microsoft Agent Framework beschreibt zusätzlich Sequential, Concurrent, Group Chat, Handoff und Magentic Orchestration.
Multi-Agent Loops sind mächtig, aber sie erhöhen Latenz, Kosten und Fehlerfläche. Ich würde sie erst einsetzen, wenn ein einzelner gut gebauter Agent mit Tools nicht mehr reicht.
7. Human-in-the-Loop
Der Mensch kann an mehreren Stellen Teil des Loops sein: als Freigabe vor riskanten Tool-Aufrufen, als Reviewer in einem Maker-Checker-Loop, als Eskalationsziel bei Unsicherheit oder als fachlicher Entscheider vor der finalen Aktion.
Gerade in Unternehmensprozessen ist das kein Zeichen von Schwäche, sondern ein Sicherheitsmechanismus. Gute Agenten automatisieren nicht blind. Sie wissen, wann sie stoppen und eine Entscheidung an einen Menschen übergeben müssen.
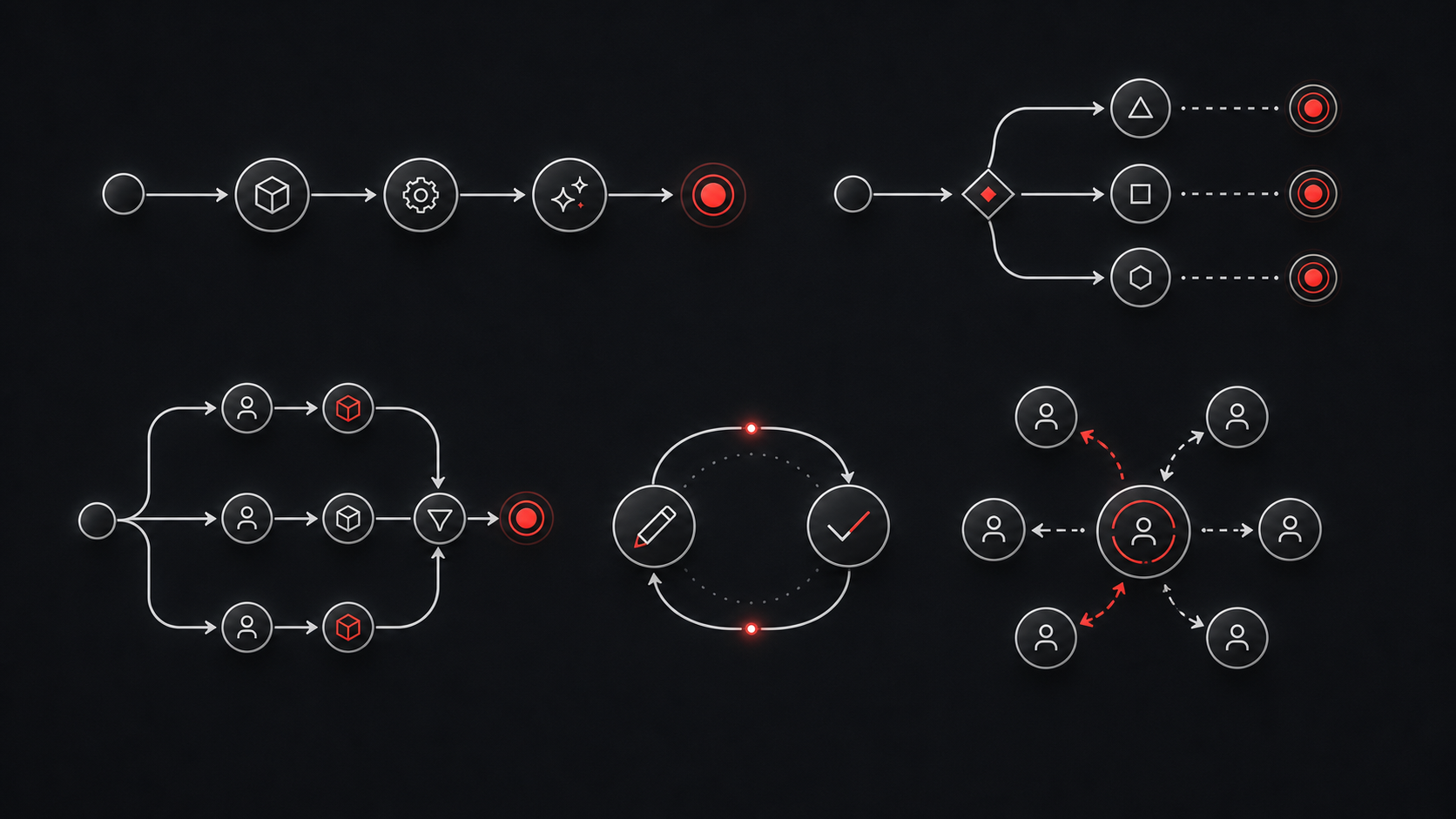
Typische Patterns im Überblick
Die wichtigsten Patterns lassen sich gut nach Steuerung unterscheiden. Prompt Chaining ist ein deterministischer Ablauf aus mehreren Schritten. Routing klassifiziert eine Anfrage und leitet sie an den passenden Pfad weiter. Parallelization lässt mehrere unabhängige Schritte gleichzeitig laufen. Orchestrator-Workers nutzt einen Koordinator, der Aufgaben verteilt. Evaluator-Optimizer erzeugt und verbessert Ergebnisse in kontrollierten Schleifen.
Dazu kommen agentenspezifische Patterns: ReAct für Denken-Handeln-Beobachten, Plan-and-Execute für längere Aufgaben, Tree of Thoughts für Suchräume, Reflection für iterative Verbesserung, Handoff für Spezialisierung und Group Chat für kollaborative Bewertung.
Wichtig ist: Diese Patterns schließen sich nicht aus. Ein realistischer Agent kann mit Routing starten, danach einen Plan erzeugen, einzelne Schritte parallel ausführen, Ergebnisse durch einen Evaluator prüfen lassen und bei Risiko einen Menschen einbeziehen. Entscheidend ist nicht, wie beeindruckend der Loop klingt, sondern ob er zur Aufgabe passt.
Welche Implementierungen gibt es?
OpenAI Agents SDK kapselt Agenten, Tools, Handoffs, Guardrails, Sessions und Tracing. Für mich ist daran interessant, dass die Schleife nicht nur als Prompt-Muster verstanden wird, sondern als Laufzeitmodell mit Ergebnissen, Ereignissen und Beobachtbarkeit.
LangChain und LangGraph sind stark, wenn man Agenten als kontrollierbare Graphen modellieren will. LangChain beschreibt den Agenten als Modell-plus-Harness. LangGraph ist besonders relevant, wenn Zyklen, Zustand, Verzweigungen und Wiederaufnahme wichtig werden.
Microsoft Agent Framework bringt die Orchestrierungsmuster stärker in Richtung Enterprise-Architektur: sequential, concurrent, handoff, group chat und magentic. Das passt gut zu .NET-, Python- und Azure-nahen Umgebungen, in denen Agenten nicht nur Demos, sondern wartbare Workflows sein sollen.
AutoGen hat früh gezeigt, wie Multi-Agent-Konversationen als flexible Abstraktion funktionieren können. Besonders wichtig finde ich dort die expliziten Termination Conditions: Ein Multi-Agent-Chat braucht klare Stop-Regeln, sonst wird aus Zusammenarbeit nur unendliche Konversation.
LlamaIndex Workflows sind interessant, wenn Agenten stark mit Dokumenten, Retrieval und eventbasierten Workflows verbunden sind. Der Agent Loop wird dort als Folge von Events und Steps beschrieben, was für persistente, nachvollziehbare Prozesse hilfreich ist.
CrewAI modelliert Arbeit stark über Rollen, Tasks und Prozesse. Sequential und Hierarchical Processes sind dort zentrale Konzepte. Das ist gut verständlich für Teams, die Agenten eher wie eine kleine Organisation aus Spezialisten denken.
Pydantic AI legt den Schwerpunkt auf typisierte Agenten, strukturierte Outputs, Toolsets, Usage Limits und Human-in-the-Loop Tool Approval. Das ist für produktive Python-Systeme interessant, weil viele Agent-Probleme am Ende Typ-, Zustands- und Validierungsprobleme sind.
Was in der Praxis oft unterschätzt wird
Der schwierigste Teil eines Agent Loops ist nicht der erste Tool-Aufruf. Schwierig sind die Grenzen: Wann darf der Agent weiterarbeiten? Wann muss er stoppen? Welche Aktionen sind idempotent? Welche Tool-Aufrufe brauchen Zustimmung? Wie wird ein fehlerhafter Lauf reproduziert? Wie verhindere ich, dass Kontextfenster, Kosten und Latenz unkontrolliert wachsen?
Microsoft warnt zu Recht vor unnötiger Koordinationskomplexität und unkontrollierten Gesprächsschleifen. Auch OpenAI und Anthropic betonen im Kern dasselbe: Starte mit dem einfachsten Loop, der die Aufgabe zuverlässig löst. Multi-Agent klingt attraktiv, aber jeder zusätzliche Agent ist auch zusätzliche Unsicherheit.
Meine Faustregel: Erst deterministischer Workflow, dann Single Agent mit Tools, dann kontrollierter Reflection- oder Evaluator-Loop, und erst danach Multi-Agent-Orchestrierung. Wer diese Reihenfolge überspringt, baut häufig Systeme, die in Demos gut aussehen und im Betrieb schwer zu erklären sind.
Meine Architekturperspektive
Agent Loops sind für mich die eigentliche Schnittstelle zwischen KI und Softwarearchitektur. Sie übersetzen probabilistisches Modellverhalten in einen kontrollierten Prozess. Der Loop entscheidet, ob ein Agent nur plausibel klingt oder tatsächlich mit Systemen arbeiten kann.
Ein guter Agent Loop hat deshalb immer fünf Eigenschaften: Er hat ein klares Ziel. Er hat begrenzte Werkzeuge. Er hat sichtbaren Zustand. Er hat harte Abbruchbedingungen. Und er hat Beobachtbarkeit über Modellaufrufe, Tool-Aufrufe, Handoffs, Guardrails und menschliche Eingriffe.
Wenn diese Eigenschaften fehlen, ist der Agent nicht produktionsreif. Wenn sie vorhanden sind, entsteht eine neue Art von Anwendung: weniger starr als klassische Workflow-Software, aber kontrollierter als ein freier Chat. Genau in dieser Mitte liegt aus meiner Sicht der eigentliche Wert von KI-Agenten.
Weiterführende Quellen
- ReAct: Synergizing Reasoning and Acting in Language Models als Grundmuster für Reason-Act-Observe-Loops.
- Reflexion: Language Agents with Verbal Reinforcement Learning zu sprachlichem Feedback und episodischer Reflexion.
- Self-Refine: Iterative Refinement with Self-Feedback zu Feedback-und-Refine-Schleifen.
- Tree of Thoughts zu Such- und Bewertungsloops über mehrere Lösungswege.
- OpenAI Agents SDK zu Tools, Handoffs, Guardrails, Sessions und Tracing.
- Microsoft Azure Architecture Center: AI Agent Orchestration Patterns zu Sequential, Concurrent, Handoff, Group Chat, Magentic und Human-in-the-loop.
- Microsoft Agent Framework: Workflow Orchestrations zur konkreten Implementierung dieser Patterns.
- LangChain Agents zur kompakten Definition des Tool-Calling-Agenten.
- AutoGen: Termination Conditions zu Stop-Regeln in Multi-Agent-Konversationen.
- LlamaIndex: Agent Loop zur einfachen Schleifenstruktur aus Input, Tool-Auswahl, Tool-Ausführung und finaler Antwort.
- CrewAI Processes zu sequential und hierarchical Prozessen.
- Pydantic AI zu typisierten Agenten, MCP, Usage Limits und Human-in-the-loop Tool Approval.
- Anthropic: Building effective agents zu einfachen, komponierbaren Patterns wie Prompt Chaining, Routing, Parallelization, Orchestrator-Workers und Evaluator-Optimizer.