Das erste Konzept aus meinem tool-agnostischen KI-Coding-Briefing ist für mich zugleich das wichtigste: Context Engineering. Es beschreibt die Disziplin, den Arbeitskontext eines KI-Coding-Systems so zu gestalten, dass gute Entscheidungen wahrscheinlicher werden und schlechte Wiederholungen seltener.
Viele Diskussionen über KI-gestützte Softwareentwicklung beginnen noch beim Prompt. Das ist verständlich, aber zu kurz gedacht. Ein Prompt ist nur die sichtbare Spitze. Die eigentliche Qualität entsteht durch das gesamte Wissensumfeld: Projektregeln, Architekturentscheidungen, Codekonventionen, Beispiele, offene Dateien, Tool-Ausgaben, Tests, externe Dokumentation und die Grenzen, innerhalb derer ein Agent arbeiten darf.
Wenn dieses Umfeld zufällig ist, arbeitet die KI zufällig. Wenn dieses Umfeld bewusst gestaltet ist, wird KI-Coding reproduzierbar. Genau deshalb ist Context Engineering kein kosmetisches Thema für Power-User, sondern eine Architekturdisziplin.
Vom Prompt zum Kontext
Prompt Engineering fragt: Wie formuliere ich diese einzelne Aufgabe möglichst gut? Context Engineering fragt: Welche Informationen muss das Modell über dieses Projekt, dieses Team, diese Architektur und diesen konkreten Arbeitsschritt haben, damit es die Aufgabe zuverlässig lösen kann?
Der Unterschied ist praktisch enorm. Bei einem Prompt muss ich jedes Mal wieder erklären, wie Tests laufen, welche Libraries erlaubt sind, wie Fehler behandelt werden, welche Architekturentscheidungen gelten und was das Modell auf keinen Fall tun darf. Bei gutem Context Engineering liegen diese Regeln persistent vor und werden nur dann ergänzt, wenn der aktuelle Arbeitsschritt es braucht.
Meine Kurzform: Prompt Engineering verbessert eine Anfrage. Context Engineering verbessert das System, in dem alle Anfragen stattfinden.
Warum alle Tools in dieselbe Richtung laufen
Die konkreten Dateinamen unterscheiden sich, aber das Muster ist inzwischen überall sichtbar. OpenAI Codex nutzt AGENTS.md als projektgebundene Anleitung. Claude Code arbeitet mit CLAUDE.md und Memory-Mechanismen. GitHub Copilot unterstützt Repository Custom Instructions. Cursor hat Project, Team und User Rules. Devin Desktop beziehungsweise Cascade beschreibt Memories und Rules auf unterschiedlichen Ebenen.
Das ist kein Zufall. KI-Coding-Tools werden leistungsfähiger, sobald sie nicht mehr bei jeder Anfrage bei null anfangen. Ein Modell, das weiß, wie dieses Repository gebaut, getestet, deployed und reviewed wird, ist ein anderes Werkzeug als ein Modell, das nur allgemeinen Programmierkontext besitzt.
Für Unternehmen ist diese Entwicklung sehr angenehm, weil das Prinzip tool-agnostisch ist. Ob die Datei am Ende AGENTS.md, CLAUDE.md, .cursor/rules oder anders heißt, ist weniger wichtig als die Frage, ob der Inhalt präzise, aktuell und wirksam ist.
Was ein gutes Kontextregelwerk beantworten muss
Ein gutes Regelwerk beantwortet nicht alles. Es beantwortet die Fragen, die sonst bei jeder KI-Interaktion erneut erklärt oder nachkorrigiert werden müssten.
1. Für wen wird Code geschrieben?
Das Modell braucht eine Vorstellung vom Team, nicht nur vom Framework. Sind die Zielpersonen Senior Engineers, Fachentwickler, externe Dienstleister oder ein gemischtes Team? Wird bewusst sehr explizit geschrieben, oder ist ein kompakter Stil gewünscht? Welche Begriffe sind im Unternehmen etabliert?
2. Wie sieht ein gutes Ergebnis in diesem Repository aus?
Hier gehören Stilrichtlinien, Test-Erwartungen, Review-Kriterien und Definition of Done hinein. Ein Agent sollte wissen, ob er Tests ergänzen muss, ob UI-Änderungen mobil geprüft werden, ob externe Links besondere Attribute brauchen oder ob generierte Artefakte verboten sind.
3. Welche Pfade, Tools und Ressourcen sind verbindlich?
Viele Fehler entstehen nicht durch schlechtes Modellverhalten, sondern durch falsche Annahmen über den Arbeitsraum. Welche Befehle bauen das Projekt? Welche Testkommandos sind relevant? Welche Ordner enthalten generierten Code? Welche Dokumente sind maßgeblich? Welche Datenbankmigrationen dürfen nicht automatisch ausgeführt werden?
4. Was darf die KI nicht?
Verbote sind kein Misstrauensvotum. Sie sind Betriebssicherheit. Kein Force-Push. Keine produktiven Migrationen ohne Freigabe. Keine personenbezogenen Daten in Logs. Keine neuen Abhängigkeiten ohne Begründung. Keine Rechts- oder Impressumstexte ohne explizite Anweisung. Gute Grenzen machen Agenten schneller, nicht langsamer.
Die drei Ebenen des Kontexts
Ich unterscheide in der Praxis drei Ebenen. Diese Trennung hilft, Kontext nützlich zu halten, ohne das Kontextfenster mit allem zu füllen, was irgendwann einmal relevant sein könnte.
Persistenter Kontext ist das stabile Projektwissen: Architekturentscheidungen, Coding Standards, Sicherheitsregeln, Teststrategie, Deployment-Pfade und Teamkonventionen. Er wird bei jeder Aufgabe geladen oder ist zumindest zuverlässig auffindbar.
Sitzungskontext entsteht während der aktuellen Arbeit: der Plan, bereits gelesene Dateien, Tool-Ausgaben, Fehlermeldungen, offene Annahmen und Zwischenergebnisse. Dieser Kontext ist flüchtiger, aber für die nächste Entscheidung oft entscheidend.
Just-in-Time-Kontext wird genau dann geholt, wenn er gebraucht wird: ein bestimmter Codeausschnitt, eine API-Dokumentation, ein Ticket, ein Log, eine Fehlermeldung oder ein Design-Screenshot. Gute Agenten laden diesen Kontext selektiv, statt die gesamte Wissensbasis vorsorglich in den Prompt zu kippen.
Token-Hygiene ist kein Detail
Ein häufiger Fehler ist, Context Engineering mit „mehr Kontext“ zu verwechseln. Das Gegenteil ist oft richtig. Guter Kontext ist nicht maximal, sondern relevant. Jede Zeile, die in das Kontextfenster geladen wird, konkurriert mit einer anderen Zeile um Aufmerksamkeit, Kosten und Verarbeitungstiefe.
Deshalb brauchen gute Regelwerke Hierarchie. Eine kurze Stammdatei sollte nur die wirklich übergreifenden Regeln enthalten. Darunter können modulbezogene Regeln liegen: Frontend, Backend, Infrastruktur, Daten, Tests, Dokumentation. Und für einzelne Aufgaben kommt Just-in-Time-Kontext dazu.
Wenn alles in einer einzigen großen Regeldatei liegt, entsteht ein neues Problem: Der Kontext ist zwar vorhanden, aber nicht mehr scharf. Das Modell sieht zu viel Gleichzeitiges, irrelevante Regeln verdrängen wichtige Regeln, und irgendwann wird die Anleitung selbst zum Rauschen.
Ein Beispiel: REST zu gRPC
Nehmen wir ein Team, das schrittweise von REST zu gRPC migriert. Ohne Context Engineering muss jede Aufgabe neu erklären, welche Protobuf-Konventionen gelten, wie Paketversionen aufgebaut sind, wann REST-Endpunkte noch bestehen bleiben müssen, welche Interceptors für Auth und Tracing verpflichtend sind und welcher Testbefehl maßgeblich ist.
Mit Context Engineering liegt diese Information als Projektregel vor. Der Agent weiß in jedem Refactoring, dass Felder in Protobuf nach einer bestimmten Konvention benannt werden, dass REST-Endpunkte nicht ohne Issue-Verweis entfernt werden dürfen, dass neue Services die gemeinsamen Interceptors nutzen müssen und dass make test-grpc der relevante Testlauf ist.
Der Effekt ist banal und gerade deshalb stark: Der Agent trifft in zehn aufeinanderfolgenden Refactorings dieselben Entscheidungen. Nicht, weil das Modell „klüger“ geworden ist, sondern weil die Arbeitsumgebung endlich konsistent ist.
Das Reifegradmodell
Context Engineering lässt sich gut als Reifegrad betrachten. Teams bewegen sich meist durch fünf Stufen:
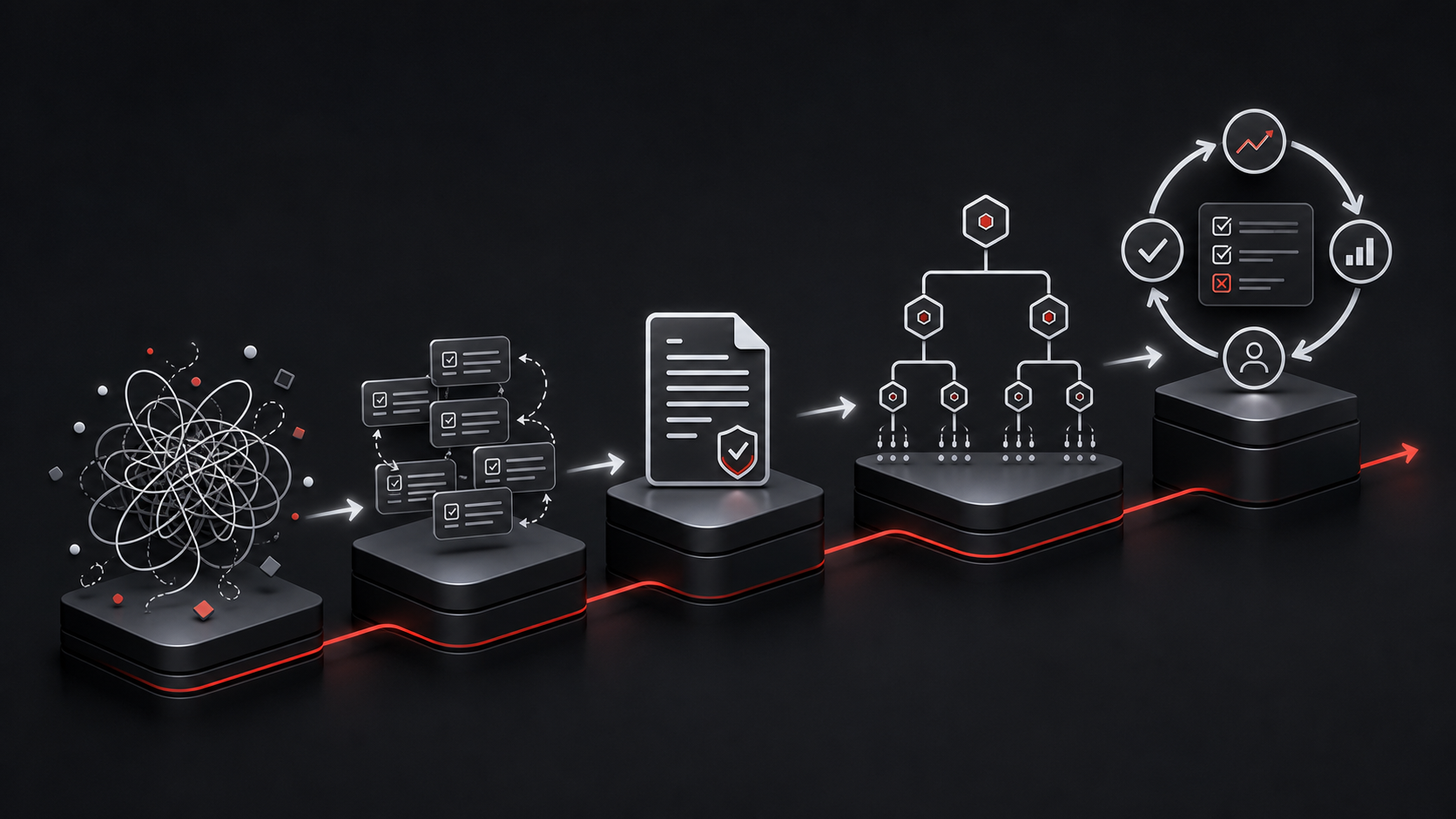
Der wichtigste Perspektivwechsel
Context Engineering bedeutet, die Zusammenarbeit mit KI nicht als Gespräch zu betrachten, sondern als sozio-technisches System. Der Mensch formuliert nicht nur Aufgaben. Er gestaltet die Umgebung, in der das Modell Entscheidungen trifft.
Das verändert auch die Verantwortung. Wenn ein Agent wiederholt denselben Architekturfehler macht, ist die Frage nicht nur: „Warum versteht das Modell das nicht?“ Die bessere Frage ist: „Wo hätte dieses Wissen liegen müssen, damit der Agent es zuverlässig sieht?“
Genau an dieser Stelle wird Context Engineering produktiv. Fehler werden nicht nur korrigiert, sondern in Regeln, Beispiele, Tests oder Evaluationskriterien übersetzt. Das Team lernt nicht nur individuell, sondern verbessert seine KI-Arbeitsumgebung.
Meine praktische Empfehlung
Ich würde jedes KI-Coding-Projekt mit einer kurzen, scharf gepflegten Kontextbasis starten. Nicht mit 300 Zeilen Wunschdenken, sondern mit den Regeln, deren Verletzung wirklich teuer wäre.
Für den Anfang reichen oft fünf Abschnitte: Projektüberblick, Build- und Testbefehle, Architekturprinzipien, Code- und Review-Konventionen, harte Verbote. Danach sollte das Regelwerk nicht wachsen, weil jemand eine Idee hat, sondern weil ein realer Fehler oder eine reale Wiederholung zeigt, dass Kontext fehlt.
Context Engineering ist damit kein Dokumentationsprojekt, das man einmal abschließt. Es ist ein kontinuierlicher Verbesserungsprozess. Jede gute Korrektur, jeder fehlgeschlagene Agentenlauf und jedes Review kann dazu beitragen, den nächsten Lauf stabiler zu machen.
Fazit
Wenn KI-Coding 2026 professionell funktionieren soll, reicht es nicht, bessere Prompts zu schreiben oder das neueste Tool einzuführen. Teams müssen ihr Projektwissen so organisieren, dass Agenten es zuverlässig nutzen können.
Context Engineering ist der Unterschied zwischen einer KI, die jedes Mal neu rät, und einer KI, die innerhalb eines klaren Arbeitsrahmens handelt. Für mich ist das der eigentliche Hebel: nicht mehr Modellintelligenz allein, sondern bessere Umgebung für diese Intelligenz.
Weiterführende Quellen
- OpenAI Codex: Custom instructions with AGENTS.md zur Idee projektgebundener Agentenanweisungen.
- Claude Code: How Claude remembers your project zu
CLAUDE.mdund projektbezogenem Memory. - GitHub Docs: Repository custom instructions for Copilot zu projektweiten Copilot-Anweisungen.
- Cursor Docs: Rules zu persistenten Project, Team und User Rules.
- Devin Desktop: Memories & Rules zu globalen, workspace- und systembezogenen Regeln.
- AGENTS.md als offenes Format für Agenten-Anweisungen in Repositories.